[YouTube Lecture Summary] Andrej Karpathy - Deep Dive into LLMs like ChatGPT
Introduction
Pre-Training
Step 1: Download and preprocess the internet
Step 2: Tokenization
Step 3: Neural network training
Step 4: Inference
Base model
Post-Training: Supervised Finetuning
Conversations
Hallucinations
Knowledge of Self
Models need tokens to think
Things the model cannot do well
Post-Training: Reinforcement Learning
Reinforcement learning
DeepSeek-R1
AlphaGo
Reinforcement learning from human feedback (RLHF)
Preview of things to come
Keeping track of LLMs
Where to find LLMs
Step 3: Neural network training
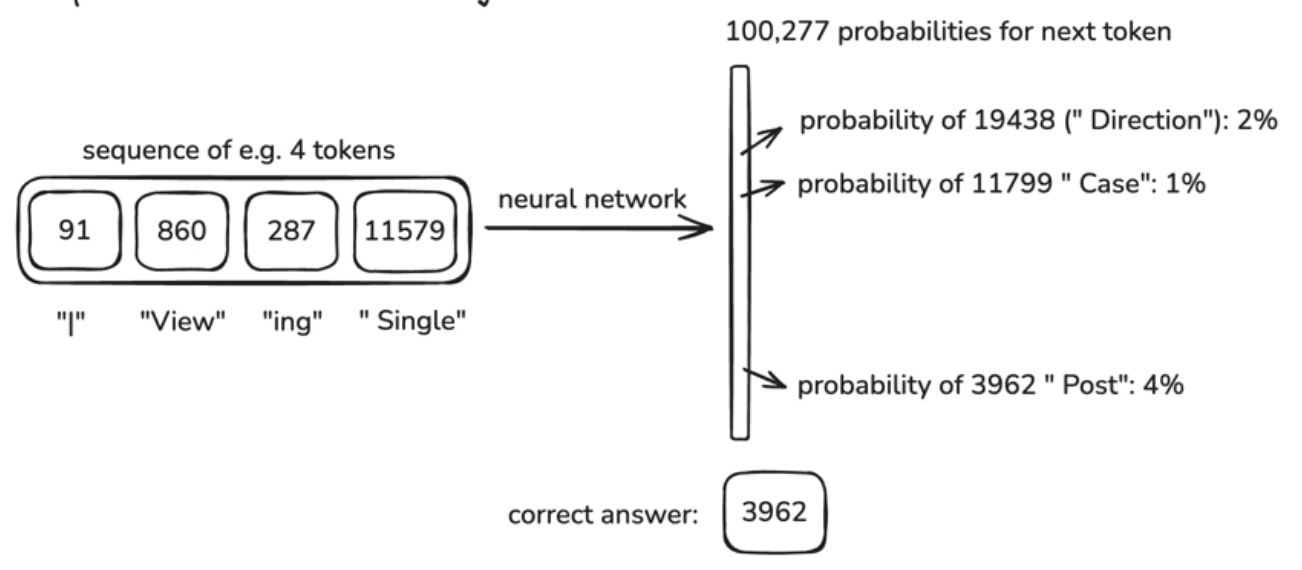
1. Neural Network Input
✅ Input data: Token sequence
The model takes numbers (Token ID sequences) as input, not text .
Example:
"Hello world" → ["Hello", " world"] → [15339, 1917] (토큰 ID)Window length: The model processes the input sentence by dividing it into fixed-length token sequences (windows) . (In the example image above, the window size is 4.)
2. Neural Network Output
✅ Output data: Next token probability distribution
The model predicts the probability distribution for all possible tokens .
Complete the sentence by selecting the token with the highest probability (Greedy Decoding)
Or generate various sentences by sampling according to a certain probability (Temperature Sampling).
3. Training Process
💡 The way the model is trained is by repeating the process of “predicting the next token”!
Input: Provide a sequence of tokens of window size.
Output: Predict the probability distribution of the next token
Calculate the loss by comparing it to the correct answer (actual next token)
Update neural network weights to reduce loss
📌 Example
Input: [“The”, “quick”, “brown”, “fox”] Output: probability distribution {“jumps”: 85%, “runs”: 10%, “flies”: 5%} Correct answer: “jumps” Loss calculation: 1 - 0.85 = 0.15 Update weights: adjust to increase the probability of correct answers
➡️ This process is repeated for billions of sentences, allowing the model to learn language patterns.