[YouTube Lecture Summary] Andrej Karpathy - Deep Dive into LLMs like ChatGPT
Introduction
Pre-Training
Step 1: Download and preprocess the internet
Step 2: Tokenization
Step 3: Neural network training
Step 4: Inference
Base model
Post-Training: Supervised Finetuning
Conversations
Hallucinations
Knowledge of Self
Models need tokens to think
Things the model cannot do well
Post-Training: Reinforcement Learning
Reinforcement learning
DeepSeek-R1
AlphaGo
Reinforcement learning from human feedback (RLHF)
Preview of things to come
Keeping track of LLMs
Where to find LLMs
AlphaGo
📄 Related papers: AlphaGo Zero paper
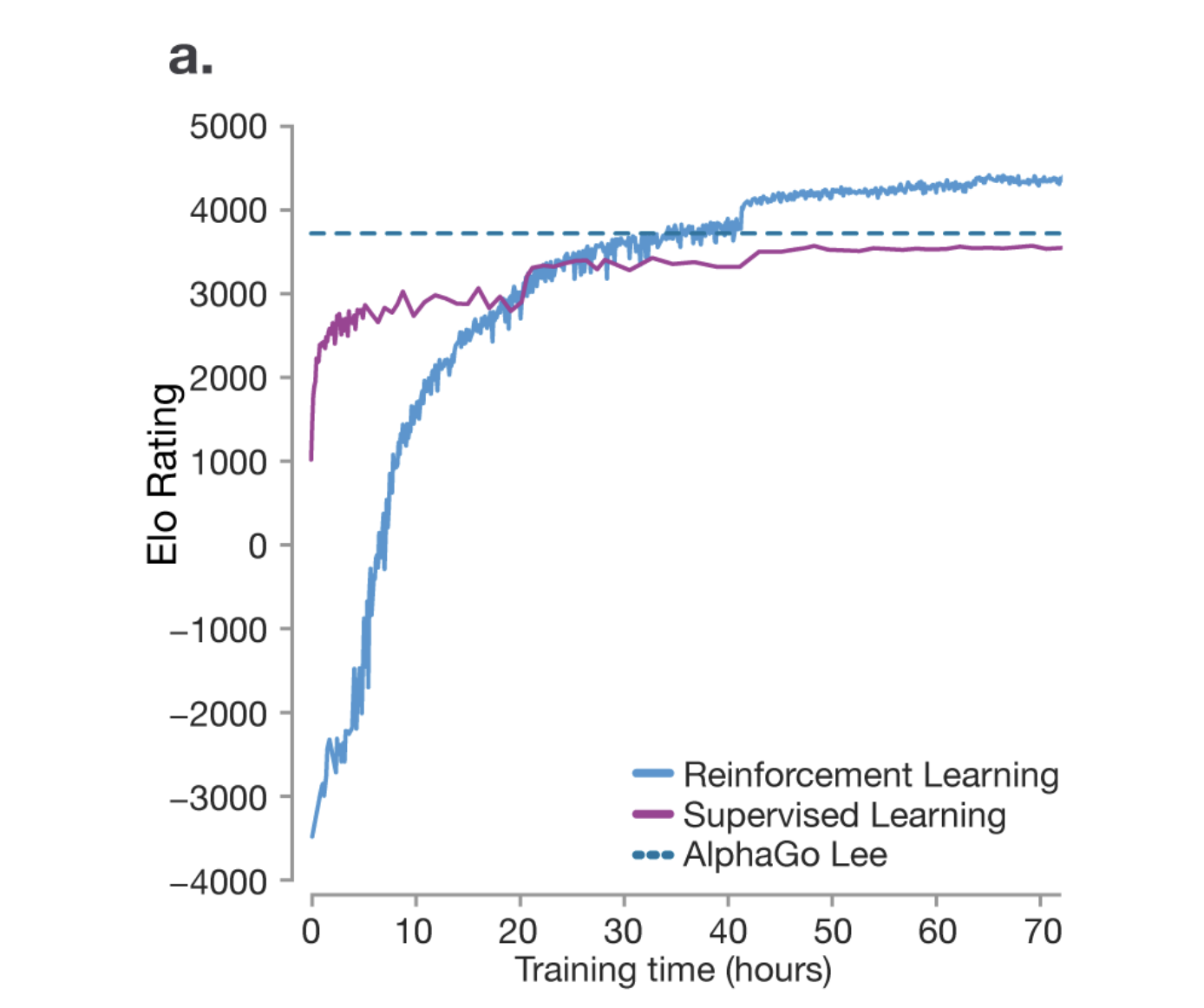
📊 Reference graph
1️⃣ Reinforcement learning (RL) is not a new concept in the AI industry.
It is already widely known in the AI industry that reinforcement learning (🎯) is a powerful learning method.
AlphaGo is a representative example of successful application of this to Go.
2️⃣ Supervised Learning vs. Reinforcement Learning
📌 Supervised Learning (purple line)
Learning and imitating the game data of human experts
Improves to a certain level, but cannot surpass the highest human level.
📌 Reinforcement Learning (blue line)
Play Go yourself and find the best strategy
Reaching superhuman abilities over time
Ultimately, AlphaGo achieves stronger performance than Lee (blue dotted line)
3️⃣ AlphaGo's groundbreaking move: 'Move 37'
AlphaGo discovers a unique move that humans rarely make (1/10,000 chance)
At the time, experts judged it to be a mistake, but it turned out to be an innovative strategy .
This is an example of how reinforcement learning can enable creative thinking that surpasses human capabilities.
4️⃣ Scalability of Reinforcement Learning 🚀
RL is now being applied to large language models (LLMs), and has the potential to go beyond simple human imitation.
Discovering new logical patterns, creative problem solving, and even the possibility of creating new languages.
Beyond games with correct answers like Go, research is underway to enable AI to develop in ‘open problems’
📌 The case of AlphaGo is an innovative case that shows that AI can not simply imitate humans, but can overcome human limitations through independent learning! 🚀